

A fintech platform came to us with a reconciliation problem.
Every day their operations team worked through an exception queue — amount mismatches, missing settlement records, FX rounding discrepancies, duplicated batches, off-cycle reversals. Each one needed an analyst to investigate, decide, and resolve. The volume was growing faster than the team could absorb
They wanted an AI feature that could triage the queue, auto-resolve the unambiguous cases with a clean audit trail, and route the genuinely ambiguous ones to an analyst — with a structured summary of what the system had already checked.
Two things were on the table from day one:
— The CFO wanted a defensible business case before any production engineering started. — The compliance lead wanted to know exactly what a regulator would see if they ever asked why the system did what it did.
We told the team we needed two weeks to answer both questions with evidence. Then we'd know whether the project was worth building.
Day One: The Spec
We did not write code on day one. We wrote a document.
The document covered one thing in detail: what counts as a correct resolution, what counts as acceptable, what counts as wrong, and crucially, the asymmetric cost of each failure mode.
For reconciliation, a false positive — auto-resolving an exception that was actually a real discrepancy — sits in a different cost class than a false negative — escalating a case the model could have safely closed. The first one is a money-movement issue. The second one is a productivity issue. The model needed to bias toward the second when confidence was low.
That asymmetry became the spec every output got measured against for the rest of the engagement.
Day Two: The Smallest Possible Harness
A single Python script. Five real exception cases pulled from the platform's production queue, anonymised. Three frontier models — Claude 3.5 Sonnet, GPT-4o, and Gemini 1.5 Pro — each given the same prompt.
Outputs went into a markdown file. A senior reconciliation analyst from the client's team sat with us and rated each one.
No vector store. No orchestration framework. No UI. Just a script.
The point wasn't to build anything. The point was to put real model output in front of real domain expertise as quickly as possible, before we made any architectural assumptions.

This is the day most engagements skip. It is the cheapest, fastest signal you will ever get on whether the project is real.
Day Three: Expanding to the Failure Modes
Five cases told us the models could handle the obvious work. That was never the question.
The real question was the hard cases. So we expanded the set to thirty.
We deliberately overweighted the categories the analyst team already knew were difficult — ambiguous FX rounding where two interpretations were both defensible, multi-leg reversals that crossed counterparties, off-cycle settlement adjustments that looked like duplicates but weren't, edge cases involving manual journal entries.
We added a fourth category to the scoring rubric: "refused" — cases where the model declined to give an answer. A model that confidently fabricated on a hard case turned out to be more dangerous than one that said "I'm not sure, send this to a human." Refusal became a feature, not a failure.
This thirty-case set became the seed eval set — the most valuable artefact of the entire two weeks.
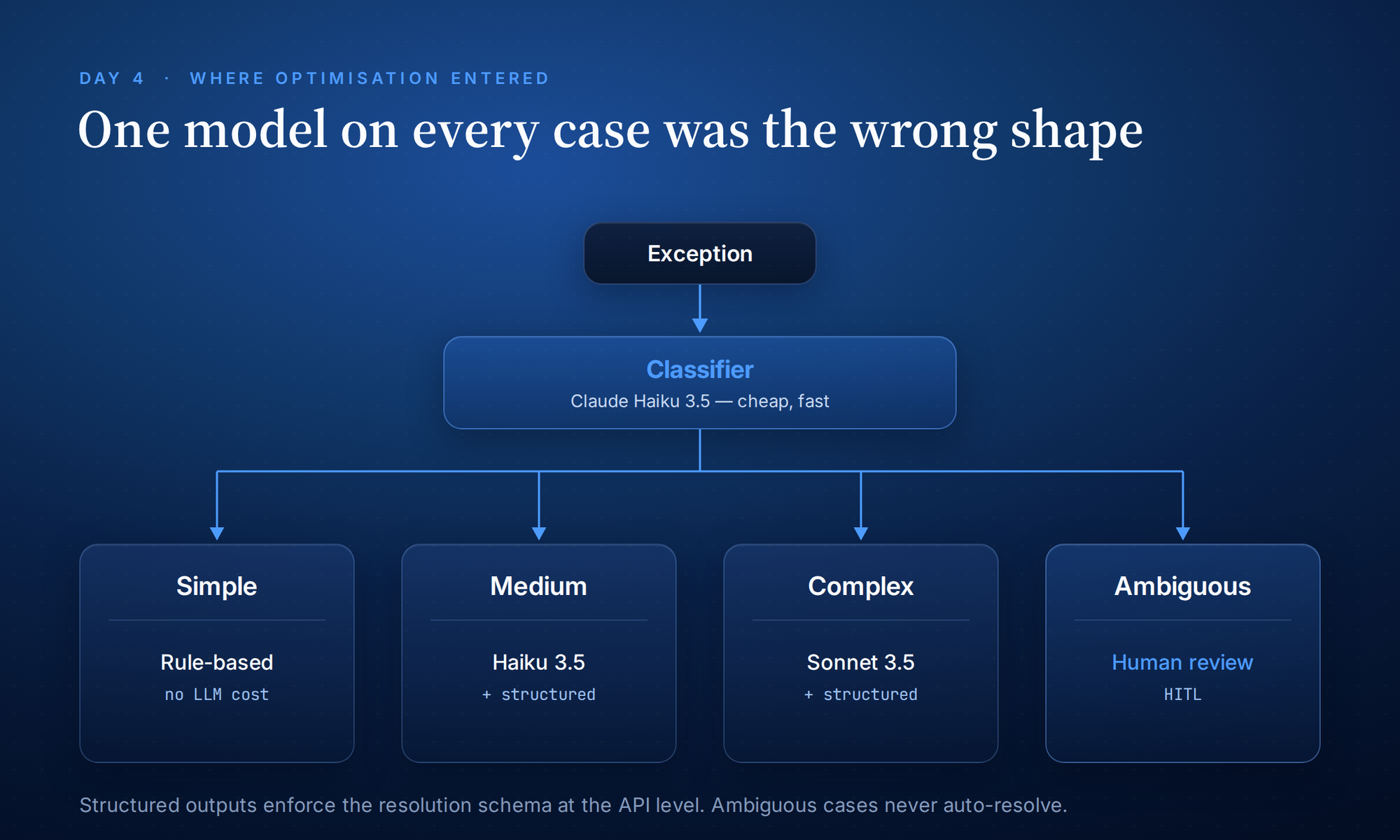
Day Four: Where Optimisation Entered
One model on every case was the wrong shape. The cost-quality curves were too different across exception categories.
We tested a routing layer instead. Claude Haiku 3.5 as the cheap, fast classifier — looking at each incoming exception and deciding which category it fell into. Easy categories routed to a cheap model with a strict prompt. Harder categories routed to Claude 3.5 Sonnet with structured outputs enforcing the resolution schema. Ambiguous categories routed directly to human review.
We also tested whether adding context helped — specifically, lookups against the platform's existing reconciliation rule library. Not a vector store, just BM25 keyword search over the rule documents (rank_bm25, fifty lines of Python). The harness ran each case twice: once without the lookup, once with it.
The lookup materially changed the model's behaviour on a specific subset of cases — the ones where the platform's internal rules differed from generic reconciliation logic. That answer locked in an architectural decision for Milestone 2: a retrieval layer would be worth building, but a simple one, scoped to the rule library only. No expensive vector store needed at this stage.
Day Five: The Dashboard and the Verdict
On day five, two things shipped: the verdict document, and a working observability stack.
For observability, we set up:
— LiteLLM as the gateway in front of every model call. It handles 429s, retries with backoff, and fails over from one provider to another when one degrades. A multi-provider setup from day one meant the AI feature could survive a rate-limit event. — Langfuse (self-hosted) as the trace store. Every request logged with model name plus version, prompt hash, retrieved context IDs, output, confidence score, latency per stage, and cost in cents. Self-hosted because data residency was non-negotiable for the regulator conversation. — Ragas for scoring retrieval faithfulness on the cases where we'd added the rule-library lookup. — Grafana sitting on top of the Langfuse Postgres for the daily dashboard.
The dashboard, in this order:
- Refusal rate by category — daily, 7-day rolling baseline
- Faithfulness score per category — daily, alerted on rate-of-change
- Latency p95 broken down by stage (classifier, retrieval, main model, post-processing)
- Cost per request, by model
- Fallback rate — how often LiteLLM switched providers
- Below-threshold queue depth — cases routed to human review
The dashboard wasn't for the demo. The dashboard was so when the model started misbehaving in week six, we'd know in hours, not weeks.
Then we wrote the verdict.
Three sections, three pages: what the model could reliably do (by category, with the eval set as evidence), what it couldn't (the categories explicitly excluded from auto-resolution scope), and what the production architecture would need to look like (routing layer, BM25 retrieval over the rule library, structured outputs everywhere, the audit log schema we'd already sketched).
We presented the verdict to the leadership team on Friday afternoon. The compliance lead signed off on the audit log schema. The CFO approved Milestone 2 funding.
What Made the Demo Reflect Production
Three things, none of them about the model itself.
Real data, never synthetic. The eval set was pulled from the platform's production queue. Synthetic test cases produce numbers that don't transfer to production.
Failure-mode coverage from day three. The eval set overweighted the hard cases. Easy cases inflate numbers. Hard cases reveal them.
Asymmetric cost framing. False positive and false negative rates got reported separately, because they cost different amounts in production. A "95% accurate" headline number is meaningless without knowing which 5% the system gets wrong.
When the production system shipped in Milestone 4, the quality numbers were within a few percentage points of what the verdict had predicted in week two. That is what "demo reflects production" looks like.
The Stack, in One Place
For anyone planning a similar engagement:
— Models: Claude 3.5 Sonnet (main), Claude Haiku 3.5 (classifier), tested against GPT-4o and Gemini 1.5 Pro — Gateway: LiteLLM — multi-provider routing, rate-limit handling, fallback — Trace store: Langfuse, self-hosted on AWS — data residency for the compliance conversation — Scorers: Ragas for retrieval faithfulness, custom Python checks for currency parsing, date formats, tenant ID integrity — Dashboard: Grafana on top of Langfuse Postgres — Retrieval (baseline): rank_bm25 for keyword search over the rule library — Structured outputs: Anthropic tool use, enforcing the resolution schema at API level — Eval harness: Python script + Jupyter, no framework
Everything else — orchestration frameworks, vector stores, prompt management systems, fine-tuned models — was deferred to later milestones. Adding tools at this stage adds confusion, not value.
What We'd Tell Any Fintech Team Planning an AI Feature
The first two weeks decide most of what comes after.
Get a small set of real cases in front of frontier models with a domain expert in the room. Build the smallest harness that can hold them. Make the eval set unfair — overweight the hard cases. Decide on the architecture from evidence, not from what other teams are doing. Stand up the observability stack before you ship a single thing.
If the work is done well, the verdict at the end of week two is the document the project is measured against six months later. The demo and the production system will tell the same story, because the same evidence built both
The next post in this series covers Milestone 2 — turning the seed eval set into a production-grade quality gate, the CI integration, and the drift monitoring that catches problems before users do.